
개요
이 글은 사내에서 Spring Batch에 대한 세미나를 진행하기 위한 강의 자료로 작성되었습니다.
Spring Batch 도입에 필요한 프로세스를 빠르게 익힐 수 있는 내용으로 구성되어 있지만,
사내 환경에 따른 의존성이나 공개되지 않은 자료가 있을 수 있는 점 참고 부탁드립니다 :)
소개
배치 처리가 무엇인가요?
AWS 클라우드 컴퓨팅 개념 허브의 배치 처리에 대한 문서의 내용에서는 아래와 같이 설명한다.
배치 처리란 무엇인가요?
배치 처리는 컴퓨터가 주기적으로 대량의 반복적인 데이터 작업을 완료하기 위해 사용하는 방식입니다. 백업, 필터링 및 정렬과 같은 특정 데이터 처리 태스크는 계산 집약적이며 개별 데이터 트랜잭션에서 실행하기에 비효율적일 수 있습니다. 대신 데이터 시스템은 대개 하루가 끝날 때나 야간과 같이 컴퓨팅 리소스를 더 일반적으로 사용할 수 있는 사용량이 적은 시간에 이러한 태스크를 배치로 처리합니다. 하루 종일 주문을 수신하는 전자 상거래 시스템을 예로 들어 보겠습니다. 시스템에서 주문을 그때그때 처리하는 대신 하루가 끝날 때 모든 주문을 수집하고 주문 처리 팀과 하나의 배치로 공유할 수 있습니다.
배치 처리가 중요한 이유는 무엇인가요?
조직에서는 사람의 개입을 최소화하고 반복 태스크를 보다 효율적으로 실행할 수 있기 때문에 배치 처리를 사용합니다. 컴퓨팅 성능을 가장 쉽게 사용할 수 있을 때 함께 처리할 수백만 개의 레코드로 구성된 작업 배치를 설정하여 시스템에 주는 부담을 줄일 수 있습니다.
- https://aws.amazon.com/ko/what-is/batch-processing/
Spring Batch는?
공식 문서의 소개글을 보면 아래와 같이 설명한다.
기업 시스템의 일상적 운영에 필수적인 견고한 배치 애플리케이션의 개발을 가능하게 하도록 설계된 가볍고 포괄적인 배치 프레임워크입니다.
Spring Batch는 로깅/추적, 트랜잭션 관리, 작업 처리 통계, 작업 재시작, 건너뛰기, 리소스 관리를 포함하여 대량의 레코드를 처리하는 데 필수적인 재사용 가능한 기능을 제공합니다. 또한 최적화 및 분할 기술을 통해 매우 대량 및 고성능 배치 작업을 가능하게 하는 보다 진보된 기술 서비스와 기능을 제공합니다. 간단하고 복잡한 대량 배치 작업은 프레임워크를 매우 확장 가능한 방식으로 활용하여 상당한 양의 정보를 처리할 수 있습니다.
- https://spring.io/projects/spring-batch
Scheduler랑은 뭐가 다른가요?
배치 작업은 위에서 보았듯 대량의 반복적인 데이터 작업을 완료하기 위한 방식이고, 스케쥴링은 배치 작업을 실행하는 방법 중 하나에 불과하다.
따라서 스케쥴링을 하지 않고, API나 다른 트리거를 통해 실행하도록 구성할 수 있다.
다만, 대개 트래픽이 적은 야간 시간대나 주기적으로 실행하는 작업이 많으므로 대부분 스케쥴링을 이용해 배치 작업을 실행하게 된다.
(그래서 개념을 혼용하여 쓰거나, 혼동하는 경우가 많은 것 같다.)
Spring Batch 시작
Spring Batch의 구성

위 그림은 공식 문서에 나와있는 Spring Batch의 전반적인 아키텍처 디자인이다.
일단 간단히 개념만 어느 정도 알아두고 코드를 작성하면서 익혀보자.
- Job : 배치의 작업 단위
- Step : Job 내에서 각각의 실행 단계
- ItemReader : 데이터를 읽어오는 단계 (DB 등)
- ItemProcessor : 데이터를 형식에 맞게 변환하는 단계
- ItemWriter : 데이터를 저장하는 단계
- JobRepository : 배치의 기본적인 CRUD를 위해 사용되며, 기본적으로 Bean으로 등록되어 있다.
- JobLauncher : Job을 실행하는 역할. 기본적으로 Bean으로 등록되어 있다.
프로젝트 생성
빠르게 Spring Batch Project를 생성해 보자.
IntelliJ IDEA에서 Spring Boot 프로젝트를 생성하고, 아래와 같이 Spring Batch 의존성만 추가하면 된다.
(그때그때 필요한 의존성은 진행하면서 추가할 것이다.)

프로젝트 초기 세팅
application.yml을 아래와 같이 작성한다.
spring:
batch:
jdbc:
initialize-schema: always
isolation-level-for-create: read_committed
job:
enabled: false
# name: jobName- spring.batch.jdbc.initialize-schema: always
- Spring Batch 관련 테이블 자동 생성 설정
- spring.batch.jdbc.isolation-level-for-create: read_committed
- Spring Batch의 기본 Isolation Level은
SERIALIZABLE이다. (DefaultBatchConfiguration의 getIsolationLevelForCreate 메서드 참고) - Isolation이
SERIALIZABLE이면 Job을 동시에 실행했을 때 오류가 발생할 수 있다.
(오라클의 ORA-08177: can't serialize access for this transaction 오류 등) - 따라서 default Isolation Level을
READ_COMMITTED으로 설정하여 위 이슈를 대응할 수 있다.
- Spring Batch의 기본 Isolation Level은
- spring.batch.job.enabled: false
- 서버 실행 시 Job이 자동으로 실행될지 여부 값으로, 필요할 때만 true로 변경하여 실행하는 게 좋다.
- spring.batch.job.name 주석
spring.batch.job.enabled가 true일 때 실행할 Job 이름.- Spring Boot 3으로 넘어오면서 Job 동시 실행이 불가능해짐에 따라 enabled가 true인 경우 Job 이름을 지정해야 한다.
https://github.com/spring-projects/spring-boot/wiki/Spring-Boot-3.0-Migration-Guide#multiple-batch-jobs
Step 만들기
Job을 만들기 위해서는 Step이 정의되어 있어야 한다.
Step은 Bean으로 등록해야 하기 때문에 Configuration 클래스를 만들어 보자.
(참고로 Spring Boot 3으로 넘어오면서 JobBuilderFactory, StepBuilderFactory는 Deprecated되었다.)
@Configuration
public class TestStepConfiguration {
@Bean
public Step testStep(
JobRepository jobRepository,
PlatformTransactionManager platformTransactionManager
) {
return new StepBuilder("testStep", jobRepository)
.tasklet(
(contribution, chunkContext) -> {
System.out.println("Hello World!");
return RepeatStatus.FINISHED;
},
platformTransactionManager
)
.build();
}
}
위에서 보았던 ItemReader, ItemProcessor, ItemWriter가 없이 tasklet으로 Step을 빠르게 생성할 수 있다.
Job 만들기
Step을 만들었으니, Job을 만들어 보자.
Job도 마찬가지로 Bean으로 등록해야 하기 때문에 Configuration 클래스를 만들어 보자.
@Configuration
public class TestJobConfiguration {
@Bean
public Job testJob(
JobRepository jobRepository,
Step testStep
) {
return new JobBuilder("testJob", jobRepository)
.start(testStep)
.build();
}
}
여러 개의 Step을 실행하고 싶으면 start 메서드 다음에 next 메서드를 계속 이어붙이면 된다.
실행하기
Application을 실행하려면 DataSource가 있어야 하는데, 일단 테스트를 위해 build.gradle에서 h2 의존성을 추가해 주자.
dependencies {
runtimeOnly 'com.h2database:h2'
}application.yml에서 배치 실행 옵션을 켜주고, 우리가 만든 job 이름을 지정해 주고 Application을 실행해 보자.
spring:
batch:
...
job:
enabled: true # 서버 실행 시 배치 자동 실행 여부
name: testJob # 배치 자동 실행 시 실행할 job 이름아래와 같이 Job이 잘 실행되고, "Hello World!"가 잘 출력됨을 확인할 수 있다.

Spring Batch 제대로 알아보기
DB 연동
DB는 JPA를 기준으로 설명할 예정이고, 사내에서 Oracle 11g를 주로 이용하는 만큼 Oracle 11g 기준으로 같이 설명한다.
먼저 아래와 같은 의존성을 추가하자.
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
runtimeOnly 'com.oracle.database.jdbc:ojdbc11'
implementation 'org.hibernate.orm:hibernate-community-dialects:6.5.2.Final'
}
최신 hibernate에서는 oracle 11g의 Dialect가 사라졌다. 대신 community-dialects에서 따로 제공하고 있어 해당 의존성도 같이 추가해 줘야 한다.
그런 다음, application.yml에 아래 내용을 추가해 보자. (oracle DB는 로컬에 임의로 띄워두었다.)
spring:
...
jpa:
properties:
hibernate:
dialect: org.hibernate.community.dialect.Oracle10gDialect
format_sql: true
highlight_sql: true
show-sql: true
datasource:
driver-class-name: oracle.jdbc.OracleDriver
url: jdbc:oracle:thin:@localhost:1521:XE
username: test
password: 1234Job 테스트는 조금 뒤에 하기로 하고, Application을 실행하기 전에 spring.batch.job.enabled 속성도 false로 바꿔주고 테스트를 진행해 보자.
Application을 실행하고 DB에 접속해 보면 아래와 같은 테이블들이 생성된 것을 확인할 수 있다.
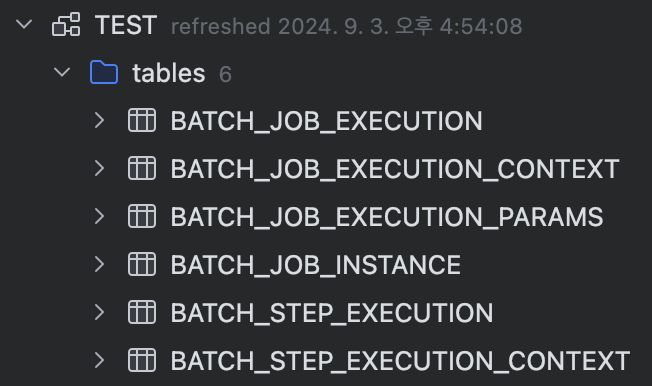
이 테이블들은 Spring Batch를 실행하기 위해 필수적으로 존재해야 하는 테이블들이다.
실행된 Job과 Step의 이력과 상태, 파라미터 등을 해당 테이블들 내에서 기록한다.
위에서 설정한 spring.bath.jdbc.initialize-schema: always 속성에 의해 Application 실행 시 해당 테이블이 없으면 자동으로 생성해 준다.
이제 제대로 Batch의 기능을 수행하기 위해 테스트 DB와 Entity를 구성해 보자.
먼저 DB에서 아래 쿼리를 통해 테이블을 생성하고, 테스트 데이터를 삽입한다.
create table MEMBER
(
ID NUMBER(19) not null
primary key,
NAME VARCHAR2(255 char)
);
create table MEMBER_DATA
(
MEMBER_ID NUMBER(19),
ID RAW(16) not null
primary key,
DATA VARCHAR2(255 char)
);
INSERT INTO MEMBER (ID, NAME) VALUES (1, '홍길동');
INSERT INTO MEMBER (ID, NAME) VALUES (2, '토토로');
그리고 이에 맞는 JPA Entity를 생성하자.
@Entity
public class Member {
@Id
private Long id;
private String name;
protected Member() {
}
public Member(Long id, String name) {
this.id = id;
this.name = name;
}
public Long getId() {
return id;
}
public String getName() {
return name;
}
}@Entity
public class MemberData {
@Id
private UUID id;
private Long memberId;
private String data;
protected MemberData() {
}
public MemberData(UUID id, Long memberId, String data) {
this.id = id;
this.memberId = memberId;
this.data = data;
}
public Long getMemberId() {
return memberId;
}
public String getData() {
return data;
}
}
이제 준비는 다 되었으니, Step에서 DB와 어떻게 동작하는지 확인해 보자.
Step 뽀개기
기존에 작성했던 StepConfiguration을 아래와 같이 수정하자.
@Configuration
public class TestStepConfiguration {
private static final int CHUNK_SIZE = 1000;
@Bean
public Step testStep(
JobRepository jobRepository,
PlatformTransactionManager platformTransactionManager,
ItemReader<Member> memberItemReader,
ItemProcessor<Member, MemberData> memberDataItemProcessor,
ItemWriter<MemberData> memberDataItemWriter
) {
return new StepBuilder("testStep", jobRepository)
.<Member, MemberData>chunk(CHUNK_SIZE, platformTransactionManager)
.reader(memberItemReader)
.processor(memberDataItemProcessor)
.writer(memberDataItemWriter)
.build();
}
@Bean
public ItemReader<Member> memberItemReader(EntityManagerFactory entityManagerFactory) {
return new JpaPagingItemReaderBuilder<Member>()
.entityManagerFactory(entityManagerFactory)
.name("memberItemReader")
.pageSize(CHUNK_SIZE)
.queryString("SELECT o FROM Member o ORDER BY o.id")
.build();
}
@Bean
public ItemProcessor<Member, MemberData> memberDataItemProcessor() {
return item -> new MemberData(
UUID.randomUUID(),
item.getId(),
"Hello " + item.getName()
);
}
@Bean
public ItemWriter<MemberData> memberDataItemWriter(EntityManagerFactory entityManagerFactory) {
return new JpaItemWriterBuilder<MemberData>()
.entityManagerFactory(entityManagerFactory)
.usePersist(true)
.build();
}
}StepBuilder
기존의 tasklet에서 chunk로 호출 메서드를 변경하고, 읽을 Entity와 쓸 Entity를 차례로 제네릭에 정의한다.
또한 하나의 작업 단위인 chunk size를 지정해야 하는데, 이는 여러 이슈에 의해 ItemReader의 pageSize와 맞춰주는 게 좋아서 전역 변수로 선언하고 가져다 쓰는 것을 권장한다.
chunk로 작업하게 되면, 트랜잭션이 chunk 단위로 수행된다. 따라서 하나의 chunk가 실패하게 되면 해당 chunk만 롤백된다.
ItemReader
DB에서 데이터를 읽어오는 단계로, 여기에서는 JpaPagingItemReader를 통해 페이징으로 데이터를 읽어온다.
순차적으로 데이터를 읽어올 때, queryString에 정렬 순서가 없으면 데이터가 잘못 읽어들여지는 이슈가 있어 ORDER BY 구문은 필수적으로 입력해주는 것이 좋다.
대표적으로 Paging 기반 및 Cursor 기반으로 이루어지며, JPA 및 JDBC로 쿼리 조회가 가능하다.
- JpaPagingItemReader
- JdbcPagingItemReader
- JpaCursorItemReader
- JdbcCursorItemReader
ItemReader가 Paging 기반인 경우 queryString을 기반으로 아래와 같이 Paging 쿼리를 자동으로 생성해서 조회한다.

ItemProcessor
ItemReader에서 읽어들인 데이터를 쓸 데이터로 변환하는 단계로, 대부분의 변환 로직은 이 단계에서 수행한다.
읽어들인 데이터를 가져와서 쓸 데이터로 return하도록 구성해야 하며, null을 return하는 경우 Write되지 않고 패스된다.
ItemProcessor는 보통 따로 구현체를 사용하지 않고, 직접 코드로 변환 작업을 하는 게 대부분이다.
(여러 ItemProcessor를 조합하기 위한 CompositeItemProcessor는 간혹 쓰인다.)
ItemWriter
DB에 데이터를 쓰는 단계로, 여기에서는 JpaItemWriter를 통해 데이터를 삽입한다.
기본적인 JpaItemWriter는 JpaRepository의 save처럼 먼저 ID로 조회하고 있으면 삽입하고, 없으면 추가한다.
불필요한 조회가 들어가는 경우 성능 저하가 있을 수 있으므로, 무조건 삽입만 이루어지는 경우 usePersist를 true로 주어 insert 구문만 실행되도록 설정할 수 있다.
- JpaItemWriter (JPA 기반으로, 작성하기는 편리하나 1개씩 save되어 성능에 좋지 않다.)
- JdbcBatchItemWriter (JDBC 기반으로, 직접 쿼리를 작성해야 하나 벌크로 저장하여 성능에 좋다.)
- CompositeItemWriter (여러 개의 ItemWriter를 조합하는 경우 사용한다.)
파라미터 추가하기
Spring Batch는 Job 실행이 성공하면 이미 성공한 작업으로 간주하여 동일한 Job을 재실행하지 않는다.
(조금 전 Oracle에서 Application을 최초 실행했을 때 spring.batch.job.enabled를 false로 둔 이유이기도 하다.)
이때 들어오는 파라미터가 다른 경우 이를 다른 작업으로 간주하여 실행할 수 있다.
또한 Job에 변수를 지정해 줘야 하는 경우도 많으므로, Job에 어떻게 파라미터를 추가할 수 있는지 알아보자.
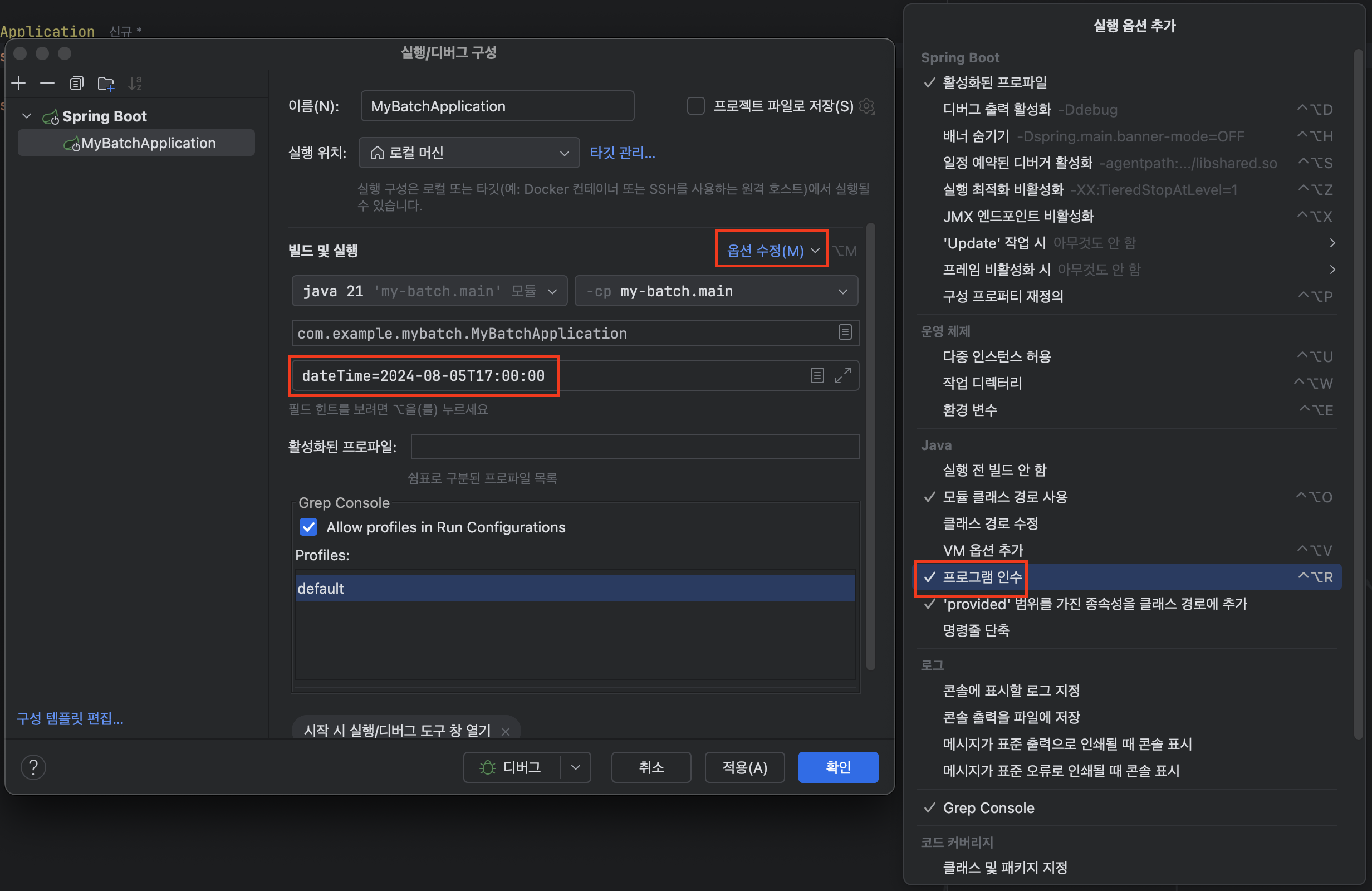
IntelliJ에서 실행/디버그 구성 > 옵션 수정 > 프로그램 인수 선택 입력창에 파라미터를 입력할 수 있다.
아래의 예시는 LocalDateTime 타입의 dateTime 파라미터를 선언했다.
Scope
파라미터를 선언한 후, @JobScope와 @StepScope 어노테이션을 통해 파라미터를 받아올 수 있다.
Step에서는 @JobScope 어노테이션으로 받아오고, ItemReader, ItemProcessor, ItemWriter에서는 @StepScope 어노테이션으로 받아올 수 있다.
@Bean
@JobScope
public Step testStep(
JobRepository jobRepository,
PlatformTransactionManager platformTransactionManager,
ItemReader<Member> memberItemReader,
ItemProcessor<Member, MemberData> memberDataItemProcessor,
ItemWriter<MemberData> memberDataItemWriter,
@Value("#{jobParameters['dateTime']}") LocalDateTime dateTime
) {
System.out.println("testJob 실행 시각 : " + dateTime);
return new StepBuilder("testStep", jobRepository)
.<Member, MemberData>chunk(CHUNK_SIZE, platformTransactionManager)
.reader(memberItemReader)
.processor(memberDataItemProcessor)
.writer(memberDataItemWriter)
.build();
}@Bean
@StepScope
public ItemProcessor<Member, MemberData> memberDataItemProcessor(
@Value("#{jobParameters['dateTime']}") LocalDateTime dateTime
) {
return item -> new MemberData(
UUID.randomUUID(),
item.getId(),
"Hello " + item.getName() + " : " + dateTime
);
}
각 메서드에서 Scope 어노테이션을 선언하고, @Value 어노테이션의 SpEL 문법을 통해 파라미터를 가져올 수 있다.
실행 결과를 확인해 보자.


Step에서 파라미터를 출력한 결과와 ItemProcessor에서 파라미터를 출력한 결과 모두 잘 확인되었다.
파라미터 검증
우리가 Job을 실행할 때 파라미터가 꼭 있어야 하는데, 파라미터가 없으면 어떻게 할까?
Job에서는 validator를 추가하여 파라미터가 없는 경우에 대해 Validation을 수행할 수 있다.
Job에 Validatior를 아래와 같이 추가해 보자.
@Configuration
public class TestJobConfiguration {
@Bean
public Job testJob(
JobRepository jobRepository,
Step testStep
) {
return new JobBuilder("testJob", jobRepository)
.validator(new DefaultJobParametersValidator(new String[]{"dateTime"}, new String[0]))
.start(testStep)
.build();
}
}DefaultJobParametersValidator의 첫 번째 배열은 필수값, 두 번째 배열은 옵셔널 값들을 지정해줄 수 있다.
이렇게 선언하고 IntelliJ의 Application 설정에서 파라미터를 없애고 Job을 실행해 보자.
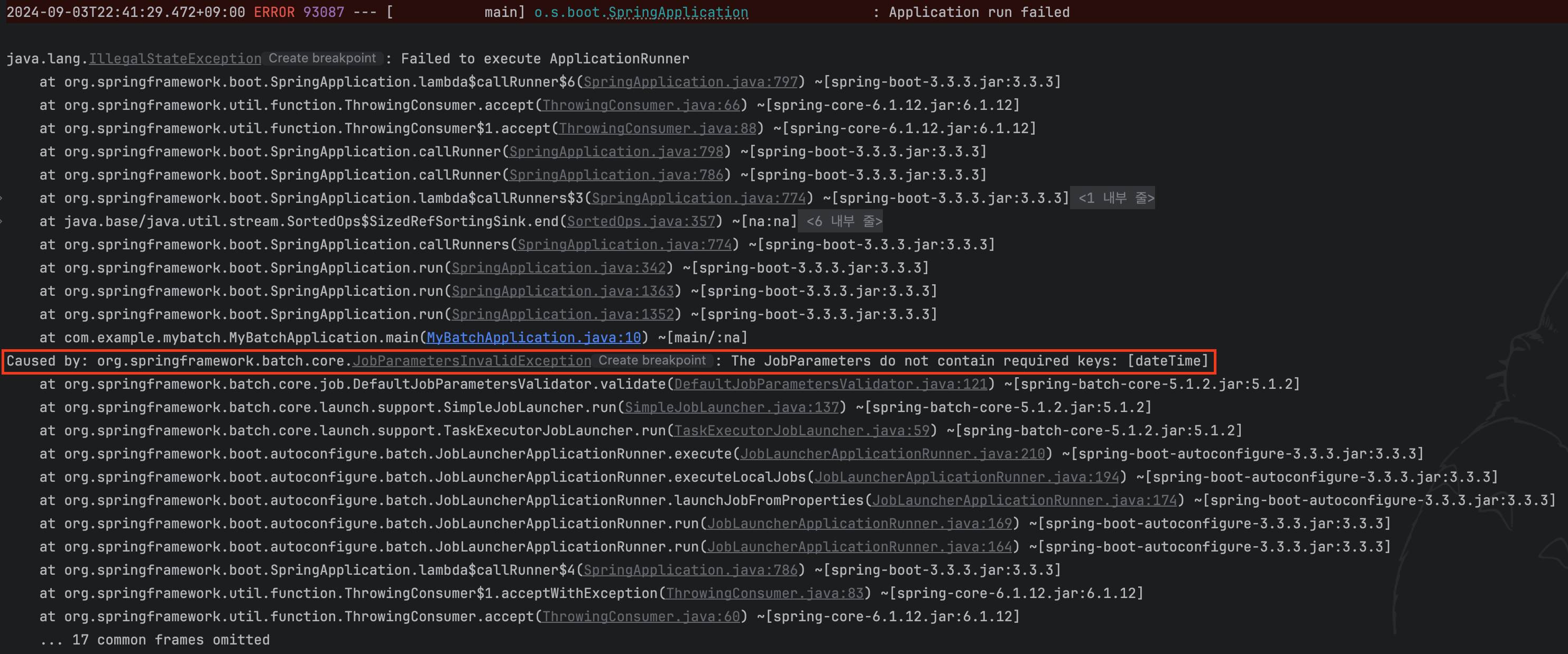
필수 파라미터가 없어서 실행이 실패한 것을 확인할 수 있다.
JobLauncher 추가하기
Job 설정에 필요한 중요한 것들을 대부분 익혔으니, 직접 Application을 실행하는 방식 말고 자체적으로 실행할 수 있도록 JobLauncher를 추가해 보자.
앞서 언급한 것처럼 배치는 대부분 스케쥴링을 기반으로 동작하므로, 스케쥴링으로 실행될 수 있도록 아래와 같이 작성해 보자.
@Component
@EnableScheduling
public class BatchScheduler {
private final JobLauncher jobLauncher;
private final Job testJob;
public BatchScheduler(JobLauncher jobLauncher, Job testJob) {
this.jobLauncher = jobLauncher;
this.testJob = testJob;
}
@Scheduled(cron = "*/5 * * * * *", zone = "Asia/Seoul")
public void testScheduler() throws JobExecutionException {
JobParameters jobParameters = new JobParametersBuilder()
.addLocalDateTime("dateTime", LocalDateTime.now())
.toJobParameters();
jobLauncher.run(testJob, jobParameters);
}
}JobParameter로 현재 시각을 넣고, 5초마다 실행하도록 스케쥴러를 구성했다.
지원하는 파라미터 양식에 따라 add로 시작하는 메서드가 존재하므로, 이를 통해 파라미터를 넣을 수 있다.
application.yml의 spring.batch.job.enabled를 false로 바꾸고 실행해 보자.
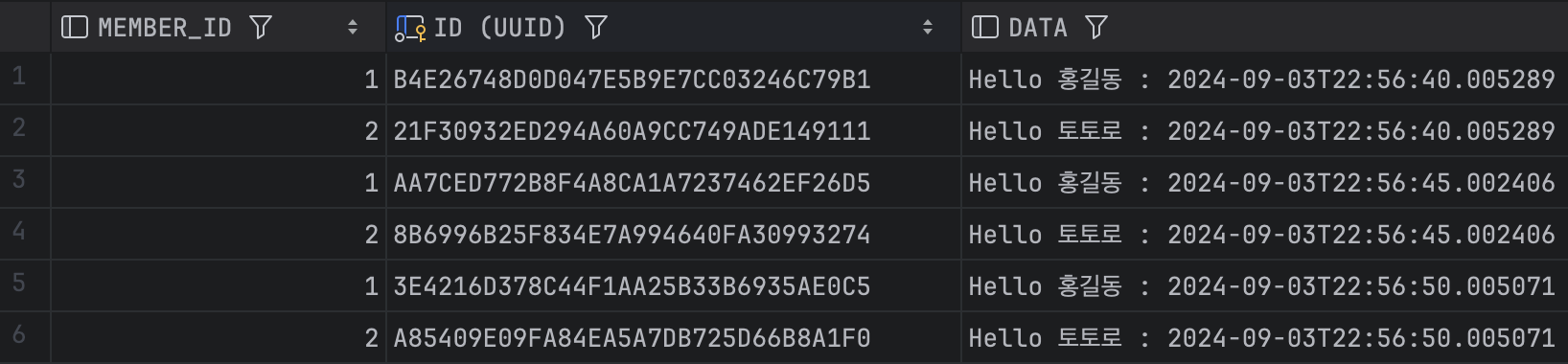
5초마다 잘 실행되는 것을 확인할 수 있다.
스케쥴러 뿐만 아니라 API 호출 시 JobLauncher.run을 하도록 하는 등 다양한 방법으로 Job을 실행할 수 있다.
Spring Batch 테스트하기
이제 Spring Batch의 Job을 실행하기 위한 대부분의 설정을 마쳤으니 잘 실행될지 검증하기 위한 테스트를 수행해 보자.
Spring Batch에서의 테스트는 전체적인 Job이 잘 실행되었는지에 대한 통합 테스트를 작성하는 것이 용이하다.
ItemReader, ItemWriter 등의 단위 테스트를 작성하려고 하면, 대부분 이미 있는 구현체를 사용하는 경우가 대다수이고, 이런 외부 구현체는 보통 테스트에 권장되지 않기 때문이다.
따라서 통합 테스트 먼저 작성해 보자.
Job 통합 테스트
테스트를 작성하기 전에,
그대로 테스트를 실행하게 되면 실제 DB와 동일한 환경에서 테스트가 실행되므로 h2를 통해 테스트할 수 있도록 test의 application.yml을 따로 작성해 주자.
spring:
batch:
jdbc:
initialize-schema: always
isolation-level-for-create: read_committed
job:
enabled: false # 서버 실행 시 배치 자동 실행 여부
# name: jobName # 배치 자동 실행 시 실행할 job 이름
jpa:
properties:
hibernate:
format_sql: true
highlight_sql: true
show-sql: true위처럼 작성하면 DB 정보가 없어 알아서 h2로 실행되게 된다.
이제 JobConfiguration의 테스트 결과를 확인하기 위해, Member를 기반으로 MemberData 테이블에 데이터가 잘 들어갔는지 확인을 위한 Repository를 만들어 보자.
public interface MemberRepository extends JpaRepository<Member, Long> {
}
public interface MemberDataRepository extends JpaRepository<MemberData, UUID> {
}
드디어 JobConfiguration의 통합 테스트를 작성할 차례다.
아래와 같이 작성해 보자.
@SpringBatchTest
@SpringBootTest
class TestJobConfigurationTest {
@Autowired
private JobLauncherTestUtils jobLauncherTestUtils;
@Autowired
private Job testJob;
@Autowired
private MemberRepository memberRepository;
@Autowired
private MemberDataRepository memberDataRepository;
@BeforeEach
void setUp() {
jobLauncherTestUtils.setJob(testJob);
}
@Test
void testJob() throws Exception {
// given
memberRepository.save(new Member(1L, "홍길동"));
// when
LocalDateTime dateTime = LocalDateTime.of(2024, 9, 3, 12, 34, 56);
JobParameters jobParameters = new JobParametersBuilder()
.addLocalDateTime("dateTime", dateTime)
.toJobParameters();
JobExecution jobExecution = jobLauncherTestUtils.launchJob(jobParameters);
// then
assertThat(jobExecution.getExitStatus()).isEqualTo(ExitStatus.COMPLETED);
List<MemberData> result = memberDataRepository.findAll();
assertThat(result.size()).isEqualTo(1);
assertThat(result.get(0).getMemberId()).isEqualTo(1);
assertThat(result.get(0).getData()).isEqualTo("Hello 홍길동 : 2024-09-03T12:34:56");
}
}@SpringBatchTest 어노테이션을 통해 Job 테스트에 필요한 의존성들을 쉽게 불러올 수 있고,
통합테스트인 만큼 운영 환경과 동일하도록 @SpringBootTest도 추가해 주자.
(@SpringBatchTest 시 의존성, 실행 구성 등을 고려하여 웬만하면 @SpringBootTest를 추가해 주는 것이 좋다.)
JobLauncherTestUtils.launchJob() 을 통해 Job을 실행하고, 그에 따른 결과가 잘 저장되었는지 확인할 수 있다.
이제 테스트를 실행해 보자.
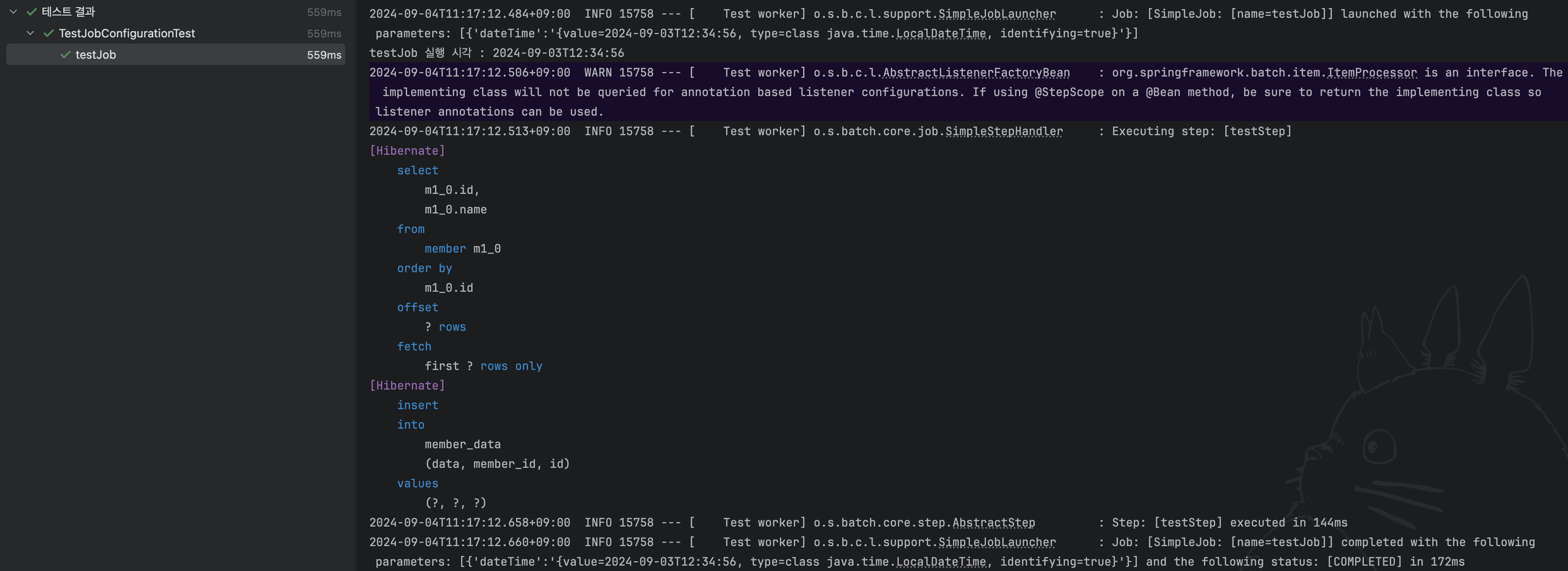
테스트가 잘 성공한 것과, Job이 잘 실행된 것까지 확인할 수 있다.
단위 테스트
위에서 설명한 대로 ItemReader, ItemWriter 대부분 이미 있는 구현체를 사용하는 경우가 대다수이기 때문에 테스트를 권장하지 않는다.
하지만 ItemProcessor의 경우 내부 로직을 직접 작성하게 되므로 테스트를 진행해 주는 것이 좋다.
따라서 우리가 작성했던 MemberDataItemProcessor가 잘 동작하는지 확인하는 단위 테스트를 작성해 보자.
class TestStepConfigurationTest {
private TestStepConfiguration testStepConfiguration;
@BeforeEach
void setUp() {
testStepConfiguration = new TestStepConfiguration();
}
@Test
void memberDataItemProcessor() throws Exception {
// given
Member member = new Member(1L, "홍길동");
LocalDateTime dateTime = LocalDateTime.of(2024, 9, 3, 12, 34, 56);
// when
MemberData result = testStepConfiguration.memberDataItemProcessor(dateTime).process(member);
// then
assertThat(result.getMemberId()).isEqualTo(1L);
assertThat(result.getData()).isEqualTo("Hello 홍길동 : 2024-09-03T12:34:56");
}
}process 메서드의 파라미터에 ItemReader에서 읽어왔다고 가정할 Member를 넣어주고,
실행 결과를 받아서 결과가 예상대로 잘 나오는지 테스트할 수 있다.
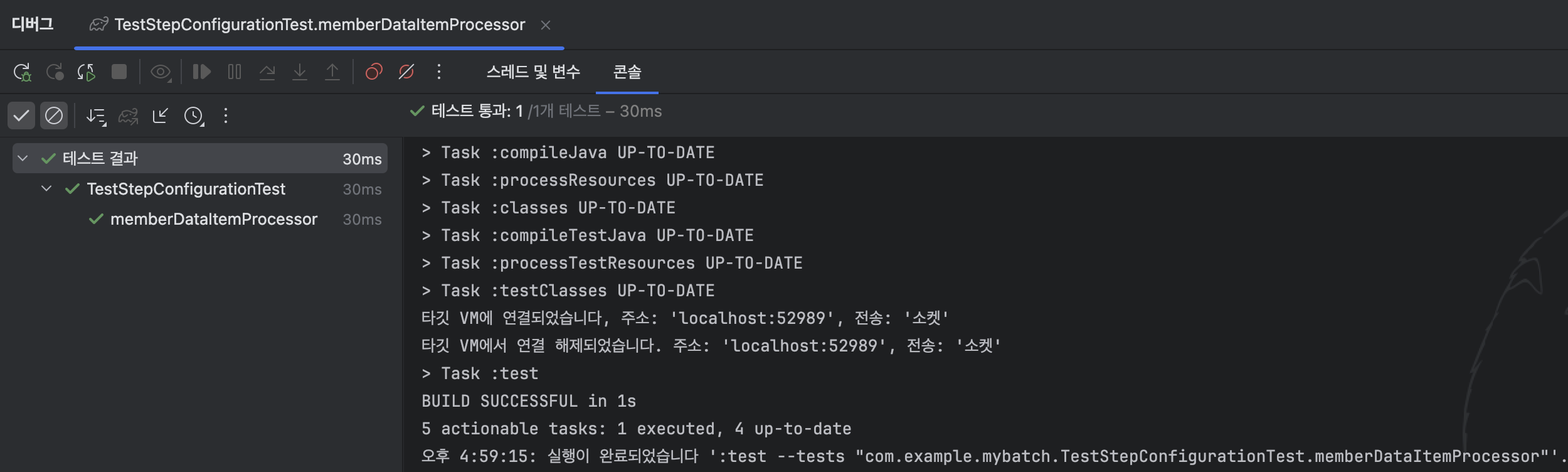
주의할 점
- ItemReader에서 StepScope를 사용하는 경우 ItemReader 인터페이스가 아닌, JpaPagingItemReader 등의 구현체를 직접 Bean으로 등록해야 한다. (https://jojoldu.tistory.com/132)
- 읽은 데이터 자체를 수정하거나 삭제하는 경우 Paging의 정렬 순서에 변화가 생길 수 있어 Cursor 기반 ItemReader를 사용해야 한다. (https://jojoldu.tistory.com/337)
- 기존 테이블 데이터를 다른 테이블로 옮기는 경우도 결국 기존 데이터를 삭제하게 되기 때문에 마찬가지.
자잘한 꿀팁
스프링 스케쥴러는 기본적으로 poolSize가 1개로 선언되어 순차적으로 실행된다.
스케쥴링을 통해 동일한 시간에 병렬적으로 실행될 수 있게 하고 싶으면 아래와 같은 설정을 추가하자.
@Configuration
public class SchedulerConfig {
@Bean
public ThreadPoolTaskScheduler threadPoolTaskScheduler() {
ThreadPoolTaskScheduler threadPoolTaskScheduler = new ThreadPoolTaskScheduler();
threadPoolTaskScheduler.setPoolSize(10); // 스케줄러 동시 실행 개수
return threadPoolTaskScheduler;
}
}
또한 스케쥴러는 로컬에서 테스트할 일이 거의 없으므로 의도치 않은 스케쥴링을 방지하기 위해 local profile일 때는 동작하지 않도록 설정해주면 마음 놓고 배치를 테스트할 수 있다.
@Profile("!local")
public class BatchScheduler {
...
}사내 프로젝트 적용 예시
지금까지 Spring Batch를 도입하기 위한 프로세스를 빠르게 알아봤다.
이러한 내용을 바탕으로, 사내에서 어떻게 도입했는지 알아보자.
적용 예시) 사내에서 Batch Application을 어떤 방식으로 도입하였는지 설명한다.
사내 Application은 첨부할 수 없으므로 자세한 내용은 생략하고, 아래와 같은 목차대로 설명한다.
- 사내 프로젝트 및 관련 도메인에서의 적용 예시
- tasklet, chunk 적용 예시
- JpaItemWriter, JdbcBatchItemWriter 적용 예시
- JpaPagingItemReader, JpaCursorItemReader 적용 예시
- Testcontainers 연동 예시
마지막으로..
Spring Batch의 더 자세한 내용들은 현 인프랩 CTO 향로님의 정리글을 추천한다.
https://jojoldu.tistory.com/category/Spring Batch
'Spring Batch' 카테고리의 글 목록
좋은 애플리케이션 구현 & 설계 / 데이터베이스 / 클라우드 / 스타트업 이야기 등을 이야기합니다.
jojoldu.tistory.com
모든 코드는 GitHub에서 확인하실 수 있습니다. :)
'Java & Spring' 카테고리의 다른 글
| [JAVA] assert 잘 사용하기 (with Spring Assert) (0) | 2024.12.11 |
|---|---|
| [Spring] Spring Boot 1.x에서 JUnit5 사용하기 (1) | 2024.10.11 |
| [Spring] 레거시 프로젝트에 Testcontainers 도입하기 (2) | 2024.07.07 |
| Spring Boot 무료로 배포하기 (Koyeb, GitHub) (0) | 2024.03.21 |
| [Spring] eventListener, transactionalEventListener 예외 및 트랜잭션 전파 총정리 (0) | 2023.12.29 |